
データを比較する際、検定という手法は非常に便利です。
しかしながら、実は非常に手間のかかる手法でもあります。
仕事においては、精度も大事ですが、それと同様、もしくはそれ以上にスピードが重要です。
都度都度データ間の有意差を知る為だけに、時間を使ってはいられないのです。
出来れば、見るからに差があると分かるデータに関しては検定なんてしたくない。
差が有るかどうか微妙なものにだけ、検定をしたい。
という事で、今回は効果量を目安にした、検定すべきデータ、検定を省けるデータの識別方法を解説いたします。

検定は大変な作業

検定のプロセス
まず、手抜きをする前に、検定という分析がどれだけ手間がかかるものか、整理しましょう。
今回は最も代表的なt検定を元に、解説を進めていきます。
①事前検証
・平均値の差と標準偏差から効果量を見積もる。
・効果量と検出力(80%)から、検定に必要なサンプルサイズをはじき出す。
②データ取り
・必要なサンプルサイズでデータを取る
③検定作業
・帰無仮説、対立仮説、有意水準を設定
・検定統計量の算出
・P値を算出し、有意水準と比較
④事後検証
・実施したときの平均値、標準偏差から実際の効果量を算出
・サンプルサイズ、効果量から、この時の検出力を算出
このようなプロセスを進めて、初めてAとBという値に差が有るとか無いとか言えるわけです。
・・・面倒くさいですね。
ただデータ間に差が有るという点を明らかにするために、ここまでするのは正直時間対効果が悪いです。
故に、出来れば省きたいのです。
あからさまに差が有るものや、差が無いものに対しては、検定を行いたくないのです。
明確に差が有るデータと差が無いデータ
例えばこんなグラフあるとします。
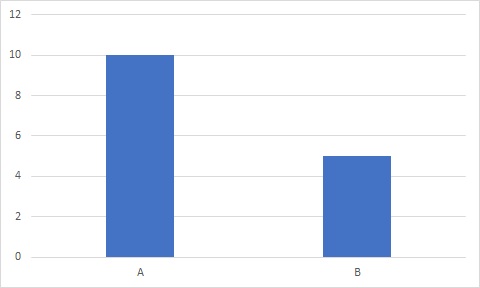
この2つのデータに有意な差がある言えるでしょうか?
言えるといったアナタ、不正解です
言えないといったアナタ、不正解です。
正解は分からないです。
このグラフには、誤差の情報が抜けているので、誤差以上の差、つまり有意差があるかどうかは分からないのです。
次に、こちらのグラフをご覧ください
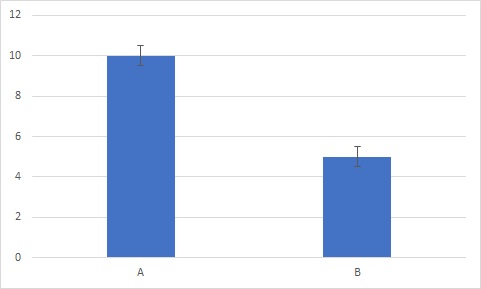
こちらのエラーバーは、標準偏差です。
これは、どう見ても差が有ると言えるでしょう。
標準偏差の2,3倍以上は、少なくとも差が有りそうですからね。
次にこちらのグラフをご覧ください。
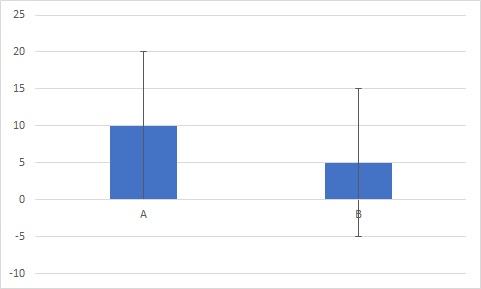
こちらのエラーバーも同じく、標準偏差です。
先程とは打って変わり、どうにも誤差範囲内の差に見えますね。
有意差なしと言わざるを得ないでしょう。
ちなみに、今見せたグラフは3つとも、棒グラフの長さ自体は全く同じです。
繰返しになりますが、誤差の情報が入るだけで、データに差が有るかどうかは全然変わってくるのです。
さて、検定に話を戻しましょう。
我々としては、無駄な検定作業は省きたい。
その為には、先述したようなあからさまに差が有る、差が無いものを対象外としたいのです。
グラフにエラーバーを導入して、描画すれば目に見えて差が有る、差が無いというのは、大体分かります。
ですが、目視判断だけでは、都度都度判断にブレが生じてしまう(そもそもブレを防ぐための検定ですが)。
なので、一発で分かる指標を準備して、それで検定作業を省くかどうかを判断出来れば、良いよなぁと思う訳です。
効果量を目安にして、検定をサボろう

効果量を目安にしよう
先程のグラフを思い出していただきたいのですが、アナタはどのようにして、エラーバーと棒グラフの値の関係性を確認しましたか?
おそらく、エラーバーの長さに対して、棒グラフの値がどれだけ離れていたのかを見ていたハズです。
これはつまり、棒グラフ同士の値が標準偏差何個分離れているのかを見ていると言えます。
このような、平均値の差と標準偏差の比は効果量そのものです。
$$Δ=\frac{μ_A-μ_B}{σ}$$
この効果量の値で、あからさまに差が有る/無い値を見極める、言い換えれば、検定すべきかどうかを見極めようというのが、今回の主題になります。
まず、差が無いという領域ですが、効果量<1と決めてしまいましょう。
以下のグラフを見て頂くと、
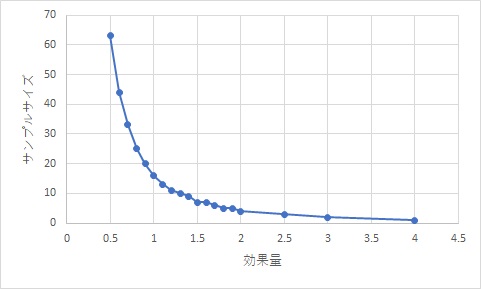
効果量が1を下回ると、検定に必要なサンプルサイズが急激に増加します。
検定において、差が有ると言いたいが為に、平均値同士の差が近すぎると、標準偏差の値を極端に小さくするために、過剰なサンプルサイズが必要になるのです。
ちなみに効果量0.8だと、こんなグラフになります。
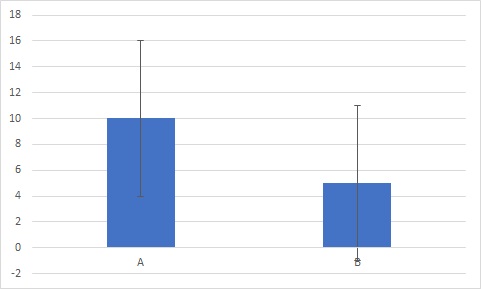
差が有るのか、微妙なラインです。
重要な案件ではない場合は、一端差が無さそうと切り捨ててしまいましょう。
次に、あからさまに差が有るという領域は、効果量>2としましょう。
これは、Z検定の場合、σ=1.96以上離れていると、両側検定で5%の有意水準に相当するからです。
t検定の場合、もうちょっと大きくなりますが、t値の分母はサンプルサイズが大きくなると、t値全体も大きくなるので、2σ以上の距離と言うのは、有意差ありを判断しても良い材料と思います。
$$t=\frac{\overline{x_A}-\overline{x_B}}{σ/√n}$$
ちなみに効果量=2をグラフにすると、
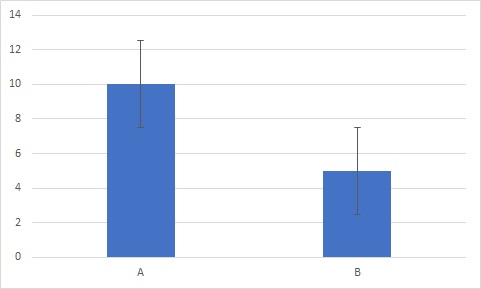
十分に差が有るように見受けられますね。
という事で、消去法で行くと、1 ≦ 効果量 ≦ 2が検定が必要な微妙なラインと言えます。
なので、効果量を先に算出して
効果量<1:差がない
1 ≦ 効果量 ≦ 2:検定実施
効果量>2:差がある
として、運用していけば、精度とスピードのバランスが良い感じに保てながら仕事で実用出来るのではないでしょうか。
まとめ
検定という作業は、本気でやろうとすると、かなり面倒です。
しかしながら、効果量という数字を目安にして、実施すべき検定のシチュエーションを狭める事で、業務の精度とスピードのバランスを保つことが可能となります。
当然、重要な場面で使うデータであれば、効果量に限らず検定を行った方が良いですが、そんなシチュばかりじゃないですからね。
身内内で軽く見せ合って、協議のネタにするとか、
データを色々いじくって、挙動を見たりとか
そんな場合は、今回の効果量の線引きは有効だと思いますので、ぜひ使ってみて下さい。
今すぐ、あなたが統計学を勉強すべき理由
この世には、数多くのビジネススキルがあります。
その中でも、極めて汎用性の高いスキル。
それが統計学です。なぜそう言い切れるのか?
それはビジネスというのは、結局お金のやり取りであり、必ず数字が絡んできます。
そして数字を扱うスキルこそが統計学だからです。
故に一口に統計学といっても、
営業、マーケティング、研究開発、品質管理、工程管理、生産管理.etc
これら全てで使う事が出来るのです。
現に私は前職は品質管理、現職は研究開発職なのですが、面接のときに
「品質管理時に活用した、統計の知識を研究開発にも活かせます」
とアピールして職種をうまく切り替える事が出来ました。
そして、もし始めるなら今から勉強を始めましょう。
なんなら、今すぐこのページを閉じて本格的に勉強を開始するべきです。
なぜなら、このような『スキル』は20代でもっともキャリアアップに繋がるからです。
30代ならいざ知らず、40代になると求められるのはこれまでの業務を遂行してきた経験や人脈なのです。
これが無いとある一定以上のキャリアアップは望めませんし、40代以降のハイクラスの転職先も望めません。
20代のうちは成果を結び付けるためにこのスキルが大いに役立ちますが、年を経るごとに求められる働き方が変わるのでスキルの実績への寄与が減ってしまうのです。
なので、後からやればいいやと後回しにすると機を逸してしまう可能性が高いです。
ちなみにこれから統計学を学習をするというのであれば、ラーニングピラミッドというものを意識すると効率的です。
私自身、インプットだけでなく、youtubeや職場でアウトプットしながら活用する事で統計リテラシーを日々向上させていっています。
ぜひ、アナタも当ブログやyoutubeチャンネルで統計リテラシーを上げて、どこでも通用するビジネスパーソンになりましょう


コメント