
データの集計、特に質的データの集計をするとき、あなたはどうしていますか?
「別に?集計は集計だろ?カウントするだけさ」
と、アンケート等で得られた情報を単純に集計していたりしていませんか?
実は、集計も工夫しだいで、量的変数のように統計的に相関関係が分析出来たりしちゃうんです。
今回は、そんな便利な集計方法、クロス集計表とその検定方法、ピアソンのカイ二乗検定を紹介いたします。
これを使うと、アンケートとかの層別分析で比較的簡単に相関関係を分析出来るので、便利ですよ。
今回はこちらの書籍の内容から解説しますので、もし気になった方は手に取ってみてはいかがでしょうか?

クロス集計って何?

どうやって集計しますか?
クロス集計とは、どんなもんなんでしょうか?
例えば、このように男女合わせて30名の生徒に好きなスポーツをアンケートしたとします。
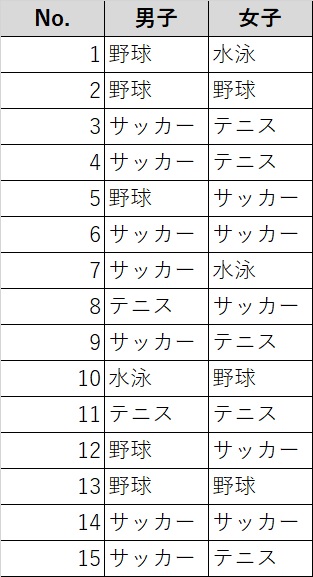
統計webより拝借:5-3. クロス集計表
表にしてまとめなさいと言われた場合、あなたならどのようにまとめますか?
こんな感じですか?
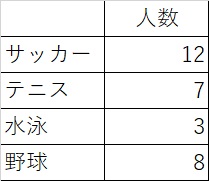
アナタ「いやいや、それじゃ男女の情報が抜けてるじゃないか!」
それならこんな感じ?
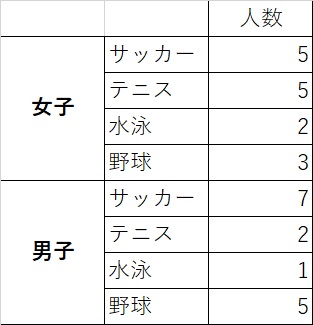
確かにこれなら、男女の情報もスポーツの情報も余さず網羅されています。
しかしながら、このまとめ方では男女の性差とスポーツの好みの関係は分かりづらいです。
クロス集計をしよう
そんな時にクロス集計の出番です。
クロス集計の場合は、このようにまとめます。
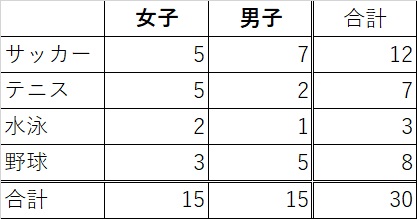
ポイントは性別という因子と、スポーツという因子がクロス上に配置されている点です。
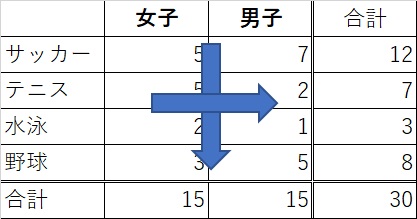
こうする事で、各因子に対しての偏りがより一層分かりやすくなります。
この表を見るに、
女子はサッカーやテニスに多少偏っているように見えますし、
男子は、サッカーと野球に偏っているように見えるし、
全体で見ると、サッカー人気がとても高いように見えます。
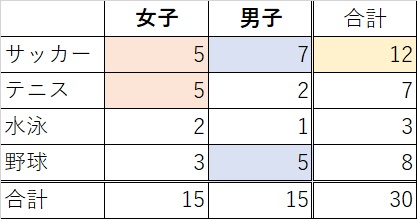
でも、その前に上げた表でもこのくらいの事は分かりそうなもんです。
態々クロス集計なんて、格好をつけたものにこだわる必要はなさそうに見えます。
確かに表として扱うなら、クロス集計にそれほど旨味はありません。
クロス集計が面白い点は、この表の数字の偏り対して、検定を実施する事が出来るという点です。
量的変数ではない、集計データで検定が実施出来るというのは、非常に興味深くないですか?
もし、これをマスターしたら、単なるアンケート調査でも統計的に分析出来るのですから、我々の分析スキルは大きく向上するはずです。
クロス集計を検定しよう

ピアソンのカイ二乗検定
クロス集計に対する検定手法を、ピアソンのカイ二乗検定と言います。
どういう原理で何を見るのか?
ピアソンのカイ二乗検定では、クロス集計表の表側項目(今回で言うスポーツ)と表頭項目(今回で言う性別)の相関性を分析します。
理論上、性別とスポーツの間に相関が無ければ、各マスに入る人数は全て等しくなるはずです。
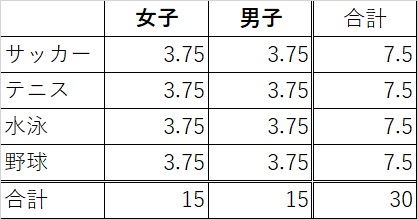
人間を唐竹割するわけにもいかんのですが、あくまで理論上という事で、人数が少数になっている点はご容赦ください。
当然、抜き取りサンプリングなのですから、毎度このようになる訳もなく、ある程度の誤差は存在し、マスの人数はある程度ばらつくでしょう。
しかしながら、もし、性別とスポーツの好みに相関があれば、その偏り方は誤差を超えたものであるはずです。
ピアソンのカイ二乗検定は、そこを分析するという訳です。
検定の流れは、基本的なものと同じです。
詳細は以下をご覧ください。
帰無仮説H0:相関性はない
対立仮説H1:相関性がある
有意水準α:5%
ここまでは、通常の検定と同じ。
肝心の検定統計量は以下になります。
$$ピアソンのx^2=\sum{\sum{\frac{(観測度数-期待度数)^2}{期待度数}}}$$
この観測度数、つまりマスの数字が相関が無い場合に期待される値と乖離しているほど、分子が大きくなるので、結果的にピアソンのx2(カイ二乗と読みます)は大きくなります。
このピアソンのx2は、カイ二乗分布に従うので、カイ二乗分布と照らし合わせて、有意水準5%より小さい確率になった場合、有意差ありとなります。
ちなみに、カイ二乗分布は1つの自由度によって、分布の形が決定されるので、自由度が1つ必要になります。
この自由度は何なのかと言われたら、表側の水準と表頭の水準の数からそれぞれ1を引いた数字を掛けた数字になります。
自由度:(表側水準数-1)×(表頭水準数-1)
これで、自由度が算出出来るので、あとは通常の検定のようにエクセルを使うなり、統計の教科書に記載されているカイ二乗分布から有意水準5%の値を引っ張ってきて比較するだけです。
さて、つらつらと書いてきましたが、これだけだとやはり分かりづらいですよね。
という事で、実際にやってみましょう。
ピアソンのカイ二乗検定をやってみた
こちらのクロス集計表に対して、ピアソンのカイ二乗検定を行います。
なんの偏りもない場合は、以下のようなクロス集計表になるはずです。
ここで各項目の
$$\frac{(観測度数-期待度数)^2}{期待度数}$$
この値を算出していきます。
例えば、女子のサッカーの場合は、
$$\frac{(観測度数-期待度数)^2}{期待度数}=\frac{(5-3.5)^2}{3.5}=0.42$$
となります。
これを各項目全てに行うと、こうなります。
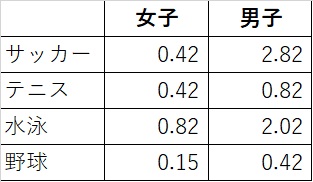
次に、これらの数字を総和します。
以下の表の右下になります。
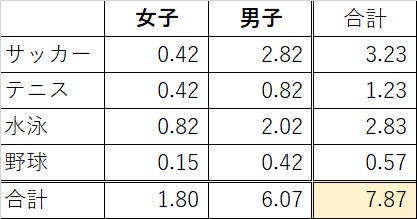
つまり、ピアソンのカイ二乗値は7.87になると言う訳です。
次に自由度です。
各水準数-1の掛け算なので、以下になります。
性別:2-1=1
スポーツ:4-1=3
自由度:1×3=3
次にカイ二乗分布の有意水準5%の点を確認します。
これはエクセルを使います。
=CHISQ.INV.RT(有意水準,自由度)
これで、カイ二乗分布における5%になるカイ二乗値が分かります。
今回の場合は
CHISQ.INV.RT(0.05,3)=7.81
となり、7.87は7.81より大きいので有意差ありという判定になります。
また、エクセルでもっと直接的に見るには、
=CHISQ.DIST(x,自由度,FALSE)
を使うと良いです。
xに先ほど求めたピアソンのカイ二乗値7.87を入力し、自由度3を入力すると
CHISQ.DIST(7.87,3,FALSE)=0.021
と直接P値が算出されます。
つまり、この値が0.05(=5%)より小さかったら、有意差ありと判定できるという訳です。
これで、先ほどの性別と好みのスポーツの間に有意差が存在する事が、検定出来ました。
まとめ
アンケートで層別情報をまとめる時には、クロス集計表を使うと、各層の偏りが見えるようになります。
また、各因子同士に相関性があるかどうかもピアソンのカイ二乗検定を使う事で分析する事が出来ます。
量的変数だけでなく、アンケート結果のような質的変数を検定出来るというのは、非常に強力な武器になります。
ぜひ、漫然とした集計ではなく、統計的な集計分析を、このクロス集計で実施してみてください。
今すぐ、あなたが統計学を勉強すべき理由
この世には、数多くのビジネススキルがあります。
その中でも、極めて汎用性の高いスキル。
それが統計学です。なぜそう言い切れるのか?
それはビジネスというのは、結局お金のやり取りであり、必ず数字が絡んできます。
そして数字を扱うスキルこそが統計学だからです。
故に一口に統計学といっても、
営業、マーケティング、研究開発、品質管理、工程管理、生産管理.etc
これら全てで使う事が出来るのです。
現に私は前職は品質管理、現職は研究開発職なのですが、面接のときに
「品質管理時に活用した、統計の知識を研究開発にも活かせます」
とアピールして職種をうまく切り替える事が出来ました。
そして、もし始めるなら今から勉強を始めましょう。
なんなら、今すぐこのページを閉じて本格的に勉強を開始するべきです。
なぜなら、このような『スキル』は20代でもっともキャリアアップに繋がるからです。
30代ならいざ知らず、40代になると求められるのはこれまでの業務を遂行してきた経験や人脈なのです。
これが無いとある一定以上のキャリアアップは望めませんし、40代以降のハイクラスの転職先も望めません。
20代のうちは成果を結び付けるためにこのスキルが大いに役立ちますが、年を経るごとに求められる働き方が変わるのでスキルの実績への寄与が減ってしまうのです。
なので、後からやればいいやと後回しにすると機を逸してしまう可能性が高いです。
ちなみにこれから統計学を学習をするというのであれば、ラーニングピラミッドというものを意識すると効率的です。
私自身、インプットだけでなく、youtubeや職場でアウトプットしながら活用する事で統計リテラシーを日々向上させていっています。
ぜひ、アナタも当ブログやyoutubeチャンネルで統計リテラシーを上げて、どこでも通用するビジネスパーソンになりましょう


コメント