

皆さんは統計手法を使う場合、
「サンプルサイズはどのくらいがいいのだろうか?」
という疑問に突き当たることはありませんか?
私はしょっちゅうあります。
統計においては、「正規性」と「サンプルサイズ」は分析精度を左右する最重要事項であるにも関わらず、ちゃんと言及している書籍を見つけるのが非常に難しいです。
特にサンプルサイズは、例外なく分析精度に関わってくる分「正規性」より重要だと思います。
私自身これから勉強していかないと、と思っている次第ではあるのですが、とはいえ普段もデータを分析する仕事は舞い込むわけで、なんとかサンプルサイズを決めてやっていかなければならないわけです(おそらく、そのような状況の方が専門家を除けば大半だと思います)
今回は、理論的裏付けは全くない話ではありますが、私がデータ採取する際のサンプルサイズを紹介していきます。
データの「感じ」をつかむ時
真剣にデータを集める前に、「ざっと」データを取りたいシチュエーションというものがあると思います。
初めて取るデータは猶更イメージが掴めないために、まずは概要把握できるレベルでデータが欲しいはずです。
そういう場合、私はサンプルサイズは「5」でとるようにしています。
「1」の場合は、当然位置づけが分からないわけです。
「2」の場合は、片方が最大値で片方が最小値に必然的になるので、分布のイメージがわきません。
「3」の場合は、そのうちの2つは先ほど述べたように片方が最大で片方が最小です。そして残りの一つのデータの収まり具合で、偏りが見えてきます。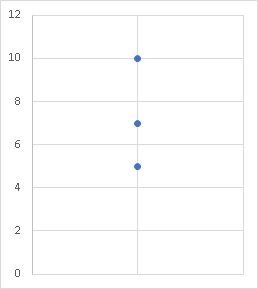 ですが、これだと実質的には真ん中の一つのデータに偏り具合をすべてゆだねている形になるので、「大丈夫かな?」と不安になります。
ですが、これだと実質的には真ん中の一つのデータに偏り具合をすべてゆだねている形になるので、「大丈夫かな?」と不安になります。
また、この中に「外れ値」が含まれていた場合、外して分析するとなると結局「2」の時と同じように最大と最小しかない状態になります。
「5」の場合は、最大値と最小値以外のデータが3つある状態です。3つのデータの偏り具合で分布のイメージがだいぶついていきます。
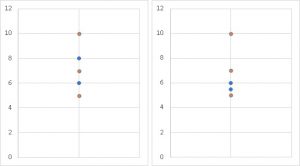
オレンジの点は先ほどの「3」の時と同じ点ですが、残り2つの点の位置で得られる分布の情報はかなり変わってきます。
ここまで来ると「あぁこういうバラツキ具合なのかな」というのが見えてきます。また外れ値を1つ除いても点が4つ残るので、簡単な分析ならまだ続行出来るわけです。
このような考えから私は、簡単にデータを取る際はサンプルサイズを「5」にしています。
標準偏差や統計的分析を実施するとき
こういうときは大体15~30くらいのサンプルサイズで分析してしまいます。
30というのはネットや書籍でも大体30くらいあれば問題ないと、推奨されている数字だったりするので使っているだけです。
ソースも根拠もはっきりしないのでそれ以上は説明できません。
しかしながら経験的にサンプルサイズが10~15を超えたあたりから、平均値に対する外れ値の影響が薄くなってきます。
なので実際に30点もサンプルを取れば、外れ値の影響はほとんど消えてしまい、平均値や標準偏差も大体安定してきている「印象」です。
そして平均値と標準偏差も安定してきたら、検定の結果もそれほどおかしくはならないのではと考えて実施しています。
しかしながら、統計量はともかく検定や推定に関しては、サンプルサイズがダイレクトに結果に効いてくる手法でもあるので、やはり少し慎重なるべきなのかもと、最近考えている次第です。
まとめ
今回紹介したサンプル数の決め方は、おそらく統計学を専門的に扱っていない多くのサラリーマンの思考に近いものなのではないかと考えています。
なぜなら、サンプルサイズの決め方をちゃんと説明した文献が中々見つからないからです。
私自身この状態はまずいとも思っているので(こんなサイトを運営している身でもありますし・・・)、勉強してアウトプット出来るぐらいには理解出来たら、また改めて記事にしたいと思っています。


コメント