
平均値間に、有意な差が存在するかどうかを知りたいとき。
統計に通じている人なら、十中八九t検定を実施します。
t検定を行う事で、平均値間の差の有意差検定が実施出来るからです。
ですが、どんなデータにもt検定を実施すると、とんだ判断違いをしてしまいます。
t検定の精度(検出力)は、効果量とサンプルサイズに依存するからです。
その検定における最適なサンプルサイズは、EZRを使えば秒で算出出来るのですが、効果量がシビアだと、かなり大量のサンプルが必要になるという事実を突きつけられることも多いです。
私自身、検定前に、効果量からサンプルサイズを算出していてふと、
「サンプルサイズを小さくするには、どのくらいの効果量にしておけば良いんだろう?」
と疑問に駆られました。
そして、
そもそも、莫大なサンプルサイズを要求されるような効果量になる測定は、本当に正しい測定なのか?
という疑問に行きつきました。
という事で今回は、効果量を、より突っ込んで考えていきたいと思います。
効果量を考える

効果量って何?
本題に入る前に、まず効果量という数字について復習しておきましょう。
効果量とは
$$Δ=\frac{\overline{x_1}-\overline{x_2}}{σ}$$
というように、平均値の差と標準偏差の比になります。
これは何を表しているのかと言えば、分布間の平均値の距離が、標準偏差に対してどのくらい離れているのかを表しています。
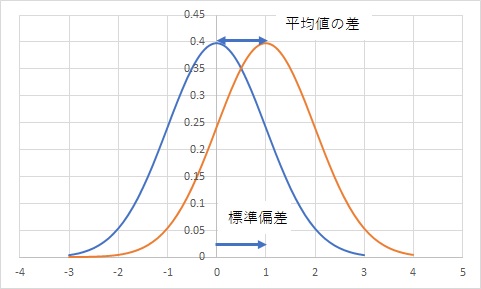
平均値の差が1で、標準偏差も1の場合は当然、効果量は1になります。
平均値の差が2で、標準偏差が1の場合は、効果量が2になります。
平均値の差が0.5で、標準偏差が1の場合は、効果量が0.5になります。
このように、平均値の距離を、標準偏差で計っているのです。
効果量は測定者が決める
効果量は統計的に決定される数字ではありません。
効果量、というより、分子に当たる平均値間の差は測定者が、それまでの経験や、技術的背景を元に決定する必要があります。
検定を行う前の準備(事前検証)の手順としては、
・このくらいの平均値の差だったら、差が有ると言えるだろうという、平均値の差を決める。
・測定実績で標準偏差を決めて、効果量を算出する
・有意水準や求めている検出力を決定する(通常は有意水準は0.05で検出力は0.8に設定する)。
・効果量、有意水準、検出力を元に、適切なサンプルサイズを導き出す。
これだけの事をした上で、検定に臨むのです。
基本的には、有意水準と検出力は一般的に決まっているので、実際のところ効果量を決定した瞬間にサンプルサイズは決定されてしまいます。
そして効果量が小さいという事は、平均値の差が小さいので、基本的に検定で有意差が出しにくくなります。
つまり、効果量が小さくなるほど、大量のサンプルサイズが必要となるのです。
という事は、サンプルサイズを出来るだけ押さえて、適切な検定を行いたいのであれば、効果量を大きく設定してやる必要があります。
ですが、平均値の差というものは、それまでの経験値や技術的背景から適切なものを選んでいるはずです。
では、標準偏差はどうでしょうか?
実はこの標準偏差は、測定の出来に左右されます。
有意差を知りたい平均値の差に対して、標準偏差が大きい場合、実はその有意差を知るためには不適切な測定になっている可能性があるのです。
cm刻みの物差しで、mm単位を測定するようなものです。
とても正しい検証とは言えません。
つまり、効果量を導くときに、不当に小さくなったら、その測定が正しくないかもと疑う必要があるのです。
それでは、どのくらいの効果量なら適切と言えるんでしょうか?
適切な効果量を考えよう

サンプルサイズの導き方
今回はEZRを使って、効果量からサンプルサイズを導きます。
EZRを開いて、【統計解析】⇒【必要サンプルサイズの計算】⇒【2群の平均値の比較のためのサンプルサイズの計算】を選びます。
次に以下のような画面が出ますので、【平均値の差】と【標準偏差】を入力して、OKを押します。
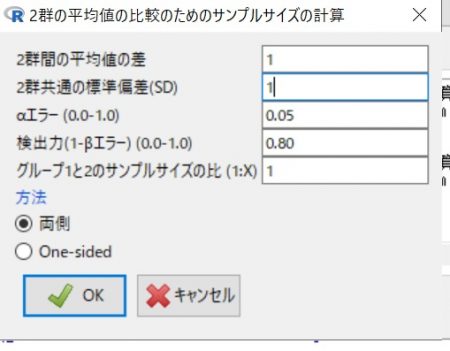
すると、出力にN数が表示されるという寸法です。
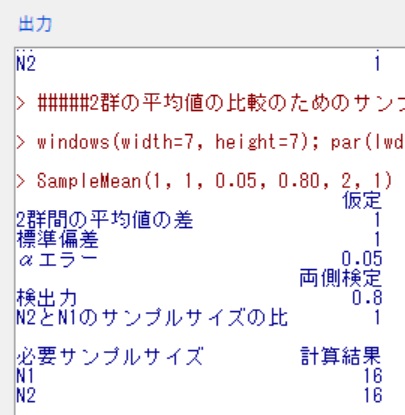
EZRをインストールしていたら、この作業、秒で終わります。
非常に簡単かつ検定で必須の作業ですので、ぜひ、取り入れて下さい。
効果量とサンプルサイズの関係
それでは、先ほどの作業で各効果量に対しての、有意水準0.05、検出力0.8におけるサンプルサイズを算出して、図にしたものが以下になります。
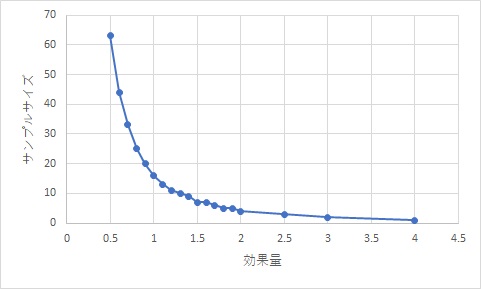
効果量が0.5~1にかけて、サンプルサイズが急激に変化しているのが分かります。
0.5~1未満というのは、標準偏差より有意差を出したい平均値の差が小さいという事を示しています。
逆に1以降(特に1.5以降)は、サンプルサイズの減少が飽和してきています。
この事から、少なくとも効果量1、出来れば1.5以上が欲しいところと言えるでしょう。
なので、もし効果量が1を割るような標準偏差となった場合、測定システムを見直す必要があります。
MSA(測定システム分析)を使って、調査するとどこに問題があるのか見えてくるかもしれません。
適切な検定フロー
以上を踏まえた上で、検定を実施する場合のフローを考えてみます。
①平均値の差を技術的背景、経験をもとに設定する。
②まずサンプルサイズ30で測定を実施する。
「えっ?それって効果量1未満じゃん。言ってること違うじゃん!」
いやいや、これは標準偏差を適切に算出するためのサンプルサイズです。
標準偏差を導くには、これだけのサンプルサイズを要するのです。
③測定結果から標準偏差を導く
④効果量を導く
この効果量が1未満なら、測定システムに問題が無いかチェックしましょう。
⑤効果量から最適なサンプルサイズを導き出す。
⑥元のサンプルから、検定に必要なサンプルサイズをエクセルのサンプリング機能でランダムにサンプリングする
効果量1以上なら、必要なサンプルサイズは30を下回るので、確実に揃えることが出来ます。
エクセルのサンプリングという機能なら、ランダムにデータを抜き出せるので便利です。
⓻Welchのt検定を実施する
分散に差が有ろうと、無かろうとWelchのt検定を実施しましょう。
⑧実施した検定の検出力を導く
有意差がある状態で、検出力が0.8を超えていたら、確実に有意差あり(検出力0.8未満なら結果を疑う)。
有意差が無い状態なら、検出力を見るまでもなく、有意差なしと判断する(最初の時点で、適切なサンプルサイズを設定しているから)
とこんな感じです。
このフローに従う事で、かなり高精度な検定を実施する事が可能となります。
まとめ
検定を行う前に、効果量が適切な値であるかチェックしましょう。
もし、効果量が1を下回っている場合、求めたい平均値の差が標準偏差より小さいという事ですから、測定システムが不適切である可能性があります。
ここを押さえて上で、検定を行えれば確実な結果を導けますし、もしかしたら今の測定システムの見えない不備を見つけるきっかけにもなるかもしれません。
今すぐ、あなたが統計学を勉強すべき理由
この世には、数多くのビジネススキルがあります。
その中でも、極めて汎用性の高いスキル。
それが統計学です。なぜそう言い切れるのか?
それはビジネスというのは、結局お金のやり取りであり、必ず数字が絡んできます。
そして数字を扱うスキルこそが統計学だからです。
故に一口に統計学といっても、
営業、マーケティング、研究開発、品質管理、工程管理、生産管理.etc
これら全てで使う事が出来るのです。
現に私は前職は品質管理、現職は研究開発職なのですが、面接のときに
「品質管理時に活用した、統計の知識を研究開発にも活かせます」
とアピールして職種をうまく切り替える事が出来ました。
そして、もし始めるなら今から勉強を始めましょう。
なんなら、今すぐこのページを閉じて本格的に勉強を開始するべきです。
なぜなら、このような『スキル』は20代でもっともキャリアアップに繋がるからです。
30代ならいざ知らず、40代になると求められるのはこれまでの業務を遂行してきた経験や人脈なのです。
これが無いとある一定以上のキャリアアップは望めませんし、40代以降のハイクラスの転職先も望めません。
20代のうちは成果を結び付けるためにこのスキルが大いに役立ちますが、年を経るごとに求められる働き方が変わるのでスキルの実績への寄与が減ってしまうのです。
なので、後からやればいいやと後回しにすると機を逸してしまう可能性が高いです。
ちなみにこれから統計学を学習をするというのであれば、ラーニングピラミッドというものを意識すると効率的です。
私自身、インプットだけでなく、youtubeや職場でアウトプットしながら活用する事で統計リテラシーを日々向上させていっています。
ぜひ、アナタも当ブログやyoutubeチャンネルで統計リテラシーを上げて、どこでも通用するビジネスパーソンになりましょう


コメント