
仮説検定(以下『検定』)は、統計を学ぶ上で、標準偏差の次に現れる2つの壁の一つです(もう一つは推定)。
この段階から有意水準や信頼区間といった、統計特有(そして強みでもある)のワードが出てきます。
この段階で統計を学ぶことをあきらめた人も多いと思います。
しかし、この検定や推定を扱えるようになると、あなたの統計リテラシーは一つ上の段階に確実にステップアップします。
今回は、検定の手法を解説する前に、まず検定のやり方のフローを解説してきます。
このフローを押さえておけば、どの検定も同様に扱えるようになります。
書籍で勉強する場合にはこちらがおススメです。ぜひご一読ください

検定とは何か
差を比較すること
検定とは差を比較することです。
特定の値と同等、統計量同士の値が等しいか、どちらが大きいか、小さいかといった様々な比較に対して有意差の有無を調べる手法です。
この手法を使えば、
「5%の確率で外れるかもしれないけど有意差あるよ」
という結果を得ることが出来ます(反対の差がないという結果に対してはもう少し詳細な条件設定が必要です。)。
この結果に対して、一定の確率の保証があるというのは大きいです。
その前の段階での統計手法では、多分差が有るという以上のことが分かりませんでした。
この多分に対して、数字の保証がつくのですから、
・上司に説明するのにも
・顧客を説得するのにも
・実験結果の信頼性を保証するのにも
役に立つということです。
覚えない手はありません。
帰無仮説を棄却する
検定は帰無仮説と対立仮説を設定し、検定の手続きを取って帰無仮説を棄却or採択します。
いきなりこんなことを言われても困りますよね。
今の一文の中で最も聞きなれないワードは帰無仮説と対立仮説だと思います。
まずはこのワードを理解することから検定の理解は始まります。
帰無仮説とは?
帰無仮説は『差がない』という仮説のことです。一般的に
$$H_0:μ_1=μ_2$$
のような形で表されます(これは平均値の差を検定する場合です)。
有意差があるかどうかを検定するので、この仮説は捨てる前提の仮説になります(それ故帰無仮説です)。

対して対立仮説は『差がある』という仮説のことです。一般的に
$$H_1:μ_1≠μ_2$$
のような形で表されます。帰無仮説に対立するので対立仮説です。
なぜ帰無仮説を設定するのか
検定は帰無仮説を設定し、棄却(文字通り捨てる)することで有意差の有無を表します。
これは言葉で表現すると
「『差がない』ということはない。よって差が有る」
というようになります。
まどろっこしいです。最初から差がないって言えないのかと私も思いました。
しかし、このような面倒な方法を取っているのにはそれなりの訳があります。
というのも、『差がある』という状況は無限通りあるのでどこまで差があれば『差がある』と言えるのか設定出来ないのです。
1=2 1=1.1 1=1.0000001
いずれも言いようによっては『差がある』と言えます。
対して『差がない』という状況は一通りしかありません。
1=1はこの一つだけです。
それ故に一通りしかない『差がない』を否定(棄却)するという方法を取ることで、有意性があることを一様に述べることが出来るのです。
検定の流れ
ここからは検定の一連の流れを説明します。すべての検定はこの流れに沿って行われるために、これを知っておくだけで検定の80%は理解出来たと言えます。
帰無仮説と対立仮説の設定
帰無仮説と対立仮説を設定します。
帰無仮説は
$$H_0:μ_1=μ_2$$
だったり
$$H_0:μ_1=3$$
のように特定の数字との比較だったり様々です。
対して対立仮説は
$$H_1:μ_1≠μ_2$$
だけでなく、
$$H_1:μ_1>μ_2$$
のように不等号を扱う場合もあります。
有意水準を設定
有意水準とは、
「この確率より小さい確率出るはずの値であった場合、偶然ではなく差が有ると判断する」
というような水準のことです。
基本的に検定は、母集団からサンプリングしたサンプル集団の代表値(平均値や分散)の検定統計量が取り得る分布を元に考えます(検定統計量は次節で解説しています)。
例えば平均値の検定統計量はサンプルサイズが極端に大きい場合、正規分布をとります。
有意水準を5%と設定した場合、標準正規分布では1.96より大きな値は5%より低い確率で発生する値です。
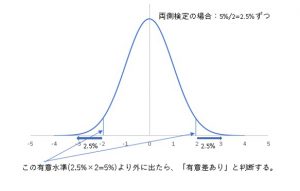
なので例えば、調査対象の平均値は0に対して有意差があるかと考える場合、この平均値の検定統計量が1.97だった場合、
「5%以下の確率で観測される値が出た」⇒「0とは有意差がある」
という風に考えます。
この有意水準ですが、基本的に5%と設定します(より厳しく実施する場合は1%の場合もあります。
検定統計量の算出
この検定統計量は様々な手法がありますが、基本概念は検定統計量を算出し、その検定統計量がとる分布と照らし合わせて、有意水準を超えるかどうかを確認するというものになります。
例えば
$$z=\frac{\overline{x}-μ}{σ}$$
は標準正規分布に従います。
このzが検定統計量に当たります。
そしてこのzが1.96を超えるか否かを比較することで、有意差の有無を確認します。
手法によって扱う検定統計量とそれが従う分布が異なります。
- 投稿が見つかりません。
P値と比較
p値とは確率の値のことで、検定統計量が何%の確率の値かということです。
例えばz=1.97であった場合、標準正規分布表から0.0488=4.88%になります。
これがp値です。この値が5%を下回った場合(有意水準を5%とすると)有意差がある判断されます。
まとめ
基本的流れは
・帰無仮説と対立仮説の設定
・有意水準の設定
・検定統計量を算出
・検定統計量と分布表を照らし合わせてp値を割りだす
・有意水準とp値を比較し、p値が小さければ有意差があると見なす
というものになります。
エクセルの分析ツールにも検定機能がついており、あの機能は検定統計量の算出から、p値の割り出しまでをやってくれます。
つまりこの流れを知っているだけで、エクセル任せで検定を実施することも可能です。
しかし、それぞれの検定の特徴を知っておかないと手法の選択ミスやサンプルサイズの設定ミスに繋がりますので、一通り各手法の概要は知っておくべきでしょう。
検定は特に中小企業では、あまり使いこなしている人が少ないです(少なくとも私が見てきた2社ではいませんでした)。
つまり検定が使用出来るという事は、かなり希少な人材と言えます。
しっかり検定を覚えて、どんどん有意差を明確に判断していきましょう。
コンテンツ紹介
昨今機械学習やディープラーニングなど、データを扱うための知識の重要度は日々増していっています。
そんな最先端のスキルを使いこなすには、土台となる統計学の知識が必要不可欠です。
しかしながら、統計学は本で読んでも何とか理論は理解できてもそこからどのように実務に活かしたら良いのか分からない。そんな机上と現実のギャップが凄まじい学問です。
そんな机上と現実のギャップを埋めるために、私は当サイトをはじめ様々なコンテンツを展開しています。
youtubeでは登録者1万人の統計学のチャンネルを運用しています。
動画投稿だけでなく、週2回のコメントに来た質問への回答配信も行っているので気になる方はどしどし質問をお寄せください。
youtubeでは無料動画だけでなく、有料のメンバーシップ限定動画も運用しています。
メンバーシップ登録リンク(押しただけで登録はされないので、気軽にクリックしてください)
エクセルやJAMOVIといった無料で使える統計ツールの実際の使い方。そして無料動画では敷居の高い(というよりマニアックゆえに再生数が見込めない(笑))解説動画をアップしています。
本を読んで実際に分析してみようと思ったけど、どうもうまくいかなかった。本では見かけない、あるいは難しすぎて扱えない手法があったという方。ぜひ一度ご参加ください(動画のリクエストがあれば反映させます)
「そうは言われても、うちのデータは統計学じゃ分析出来ないよ」
そういう方もいらっしゃると思います。私の経験上、そういったデータ分析が出来ない状況の一つとして量的変数として目の前の現象を扱えていないというものがあります。
私のnoteでは、過去私が製品開発を行う上で実践した分析しやすい数値の測定方法を公開しています。
私が開発活動する上で創意工夫を凝らして編み出してきたアイデアの数々を公開しています(私の知見が増えたら更新していきます)。本やネットではまず載っていません。うまい測定方法のアイデアが浮かばないという方はぜひこちらをご覧ください。
「いや、その前に使える手法を体系的に学びたいんだけど」
そんな方には、udemyの講座を推奨します。
初歩的な標準偏差から、実験計画法、多変量解析まで、実際に私が実用する上で本当に使用したことがある手法に絞って順序立てて解説しています。
どの手法が結局使えますのん?という方はぜひこちらをお求めください。
こんな感じで、様々なコンテンツを展開しています。
今後は品質工学や品質管理に重点を絞ったコンテンツなども発信していきます。
ぜひリクエストがありましたら、それらも反映させていきますのでまずはお気軽にご意見くださいな。


コメント